The Modern Webseed
Seeding when you can't torrent bits
BitTorrent is great, but what if you, graceful and mighty but in adverse network conditions, cannot run a torrent client?
Sciop has just the feature for you! As of today1 you can now add webseeds straight from the website! This means that we can bridge datasets archived in any number of traditional archives, efficiently use existing resources, and bring a new category of institutionalized peers into the swarm.
This work builds on one of our attempts at revitalizing the broader bittorrent tooling ecosystem,
where after integrating torrent-models2
we can now safely3 and transparently make serverside edits to uploaded torrents.4
Stick around after the ad break to learn how webseeds could enrich your life and make you more complete as a person.

How It Works
Webseeds are very simple and require no special behavior on the part of the HTTP server aside from supporting range requests. Where normally the bittorrent client would request pieces from other peers, the client instead requests ranges from the http server. Webseeds can be used along with normal peer swarms, and multiple webseeds can be used at once.
Webseed URLs are constructed like this for multi-file torrents:
{webseed_url}/{torrent_name}/{path}
and like this for single files:
{webseed_url}/{torrent_name}
where torrent_name is the value of the name field in the torrent’s infodict
(not the filename).
The name field is the name that’s shown in your torrent client and the folder that is created when you download a torrent.5
So for a torrent named tentacoli with a file named track-07.mp3,
if an http server was hosting that file at https://example.com/desktop/tentacoli/track-7.mp3
then the webseed url would be https://example.com/desktop/.
Adding A Webseed
If you have hosted some data in a torrent somewhere, or are aware of some alternate source for it, you can add it to the torrent from the web interface6
When you are logged in to sciop, on an upload page, you will see a button to add a webseed.
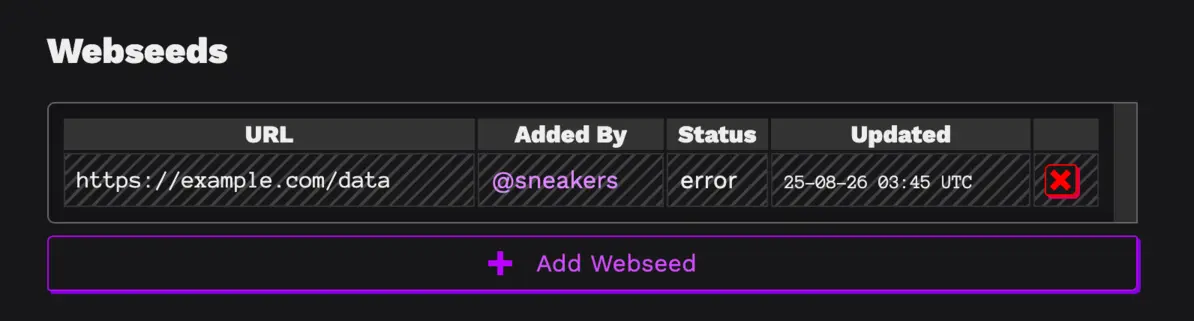
If you click it, you can then type in a url
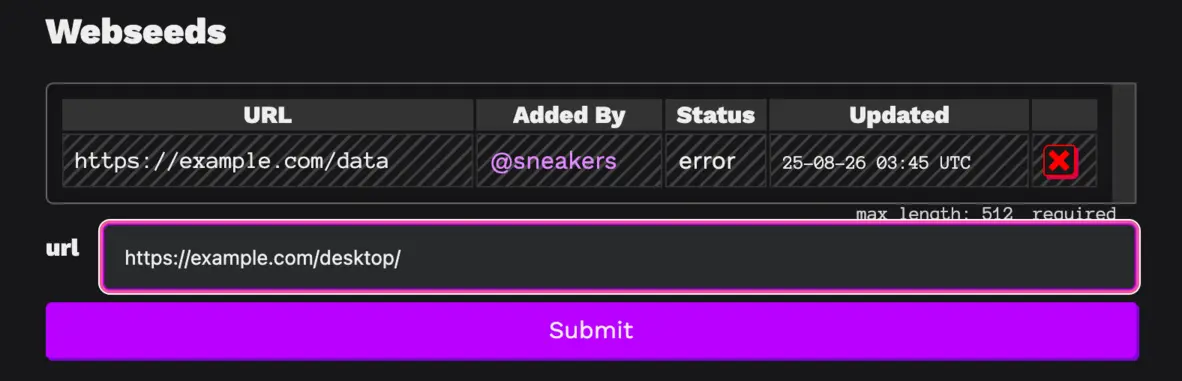
And once you submit it, it will be added to the validation queue
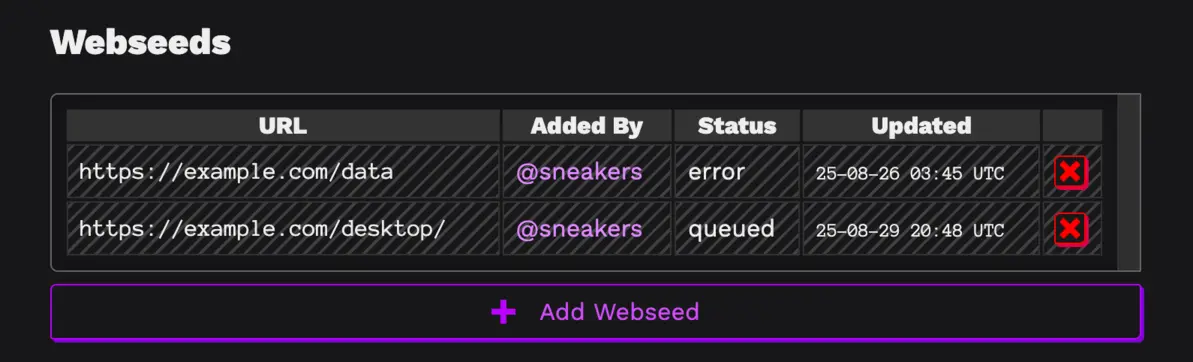
The server will now attempt to validate that the URL works as a webseed by requesting some subset of the pieces and checking them against the piece hashes in the torrent.7
If the webseed validates, if the account that added it has the upload permission scope,
then it will be added to the torrent!
If the account does not have the upload scope,
it will enter the moderation queue and only added after manual review by a moderator.
The account that uploaded the torrent retains control of the torrent,
so they are able to remove webseeds if they object to them for some reason,
and webseeds from accounts without upload permissions are not
displayed publicly until they are approved to avoid them being a vandalism vector.
This follows the general soft security moderation pattern of sciop - rather than gatekeeping at the level of account creation, any account can propose a change to be made, but only known accounts automatically have those changes take effect. This allows us to keep the site trustworthy while allowing everyone to participate.
Why This Is Cool
What’s the big deal, it’s just adding a url to a list in a torrent? Like objects in mirrors, webseeds in blogposts are cooler than they appear.
We are not aware of any other trackers that allow post-hoc addition of validated webseeds in a participatory way by people that aren’t the original uploader, but please let us know if we missed something.
Institutional Pipes
As much as we would love for everyone to experience the joy of a torrent swarm, many would-be collaborators have been unable to contribute because their resources are housed in some setting where bittorrent traffic is blocked, or it would otherwise be impossible for them to run a torrent client. This has been a common refrain from our colleagues at academic institutions or archives.
We are not protocol purists, and don’t use bittorrent for bittorrent’s sake, but instead use it to bring all available resources to bear from cute little raspis seeding from a flash drive to enormous Swedish Seedboxes. What are HTTP servers and S3 buckets but very big peers?
Adding webseeds via the web UI provides a new way for those in constrained circumstances to join the swarm by getting the data8 and rehosting it on a traditional HTTP server. We also hope to incentivize joining the swarm by providing a little pro-social gamification - having your URL listed as a webseed on sciop lets others know that you care about the preservation of cultural memory.
Bridging Archives
Archives have a problem: there are more than one of them. This is a problem for preserving threatened data, where different archival groups have been patching together dataset storage on zenodo, google drive, globus, and so on; as well as for more conventional archiving, where researchers have to search or upload their work to multiple archives that are mutually incompatible.
Aggregation and indexing overlays address this problem to some degree by collecting potentially multiple links to the potentially multiple places a dataset might be hosted, but they don’t make use of those multiple hosts, allowing the redundancy of resources to improve availability, resilience, and performance. Even if a dataset is hosted in multiple places, I still have to download it from only one of them, so the fastest and largest archives end up shouldering all the costs and smaller archives don’t have a great “path to relevance” - why would i store my data on the slow, unpopular archive?
Treating a torrent as a verifiable shorthand for a dataset and then allowing anyone to add a webseed means that now it is possible to make use of all the available resources for a given dataset - if i have previously archived something to zenodo, or on my special S3 bucket server9, and I see someone uploaded it to sciop, I can add in my copy as an additional source. When multiple webseeds are present, bandwidth can be shared between each of them (and the rest of the swarm), decreasing the burden on each individual host.
This allows sciop to take indexing overlays one step further - rather than just aggregating the metadata from multiple hosts, we can aggregate the hosts themselves.
Division of Labor - Scrapers & Seeds
Sciop as a project is about coordinating people with varying resources, expertise, and commitment towards the same goal - it should be possible for someone to wander in off the street10 and contribute, whether that means spending 5 minutes improving the docs or 5 months scraping alongside us.
We have observed a natural division of labor emerge, where people often fall into one or a few basic roles based on expertise or interest. One of those divisions has been between scrapers and seeders - where some people love to do the work of scraping and downloading, but don’t have the resources to actually store and upload it; and others don’t enjoy scraping but have plenty of spare storage and bandwith.
The pattern of
- low-resource scrapers downloading, hashing, and discarding data
- uploading a torrent with a webseed, and
- other seeders bootstrapping the swarm off the webseed
has proven to be ridiculously effective.
This provides a way for people without seeding resources to effectively call down a swarm of seeders onto an at-risk dataset, who then automatically11 and collaboratively back it up. This process is much more respectful to the hosting servers than everyone scraping their own copy would be, as in the ideal case the webseed needs to only upload the full dataset twice,12 and then all future downloads have bandwidth supplemented by the swarm. Scraping is additionally deduplicated by our quest system and scraping tools that turn web archiving into an all-play activity, and will be the subject of a future blog post :).
Adding the ability to add webseeds after the fact extends that by being able to adapt in the case that the dataset moves, as well as opens up new opportunities for labor division, where scouts aware of copies of data being held in other places e.g. by other archival groups can do the curation work of adding those to the swarm.
TODO
There are a number of obvious expansion points we’ll be pursuing
- The multiple-use of the
namefield for display and as part of the url in a webseed is a big pain in the ass. this is the reason that, e.g. when downloading the TIF archive of the NMAAHC, one ends up with a million torrents with the same name.13 This also poses a problem when the relevant files are not all stored under one subdirectory, or have urls for files with any other naming structure but that of the torrent. We want to create a plugin for sciop that allows you to use a sciop URL as a webseed-by-proxy that then redirects to the appropriate URL on the webseed server, and in the future we’ll be working on our own client that escapes some of the stagnation of current clients and decouples thenamefield. - When a webseed is added on the server, it is not added to clients that have already downloaded the torrent.
We’ll be writing a general
syncfunction for sciop-cli that resolves this and other torrent mutability problems at the client level, updating existing torrents with new metadata, replacing torrents that have been superceded by a repack, and so on. - Validating files in a torrent against a webseed url is almost the same operation as creating torrents from a url. We want to support that for, e.g., using spare server resources to create torrents when scraping resources are thin, as well as for “importing” datasets from other archival systems. This also opens up interesting possibilities for hybrid http/bittorrent-backed web archives for, say, replaywebpage from webrecorder, but more information on that is TBD
- We’ll also be adding stats to account pages to encourage adding webseeds, it’s good to be able to brag about doing good things!
If you’d like to get involved with these or any other sciop projects, you are more than welcome to hop on the issues, or contact me or anyone else in SRC to ask to be added to our contributor chat <3
Appendix on Malicious Use
What about privacy? isn’t making people ping a server a whole attack vector?
Adding arbitrary webseeds is no more of an information leak than being able to add arbitrary peers to a swarm. Anyone who wanted to surveil the swarm could do so far more easily by simply joining it or scraping trackers.
Sciop validates a random subset of pieces from any added webseeds before adding them into torrents, and since the selected pieces are random, it would be relatively hard to fake hosting some tiny subset of the data and yield zero reward. If a webseed were to try and serve copies of the data spiked with malware, torrent clients would reject it since it doesn’t match the piece hash and ban the webseed IP.
However if there is some security or privacy risk that we failed to consider,
please submit an issue
or contact us privately at contact (at) safeguar (dot) de if raising an issue could compromise sciop’s security.
-
Actually not today, for a week or so, but it was broken and we were letting shrimp have the first dibs. ↩
-
“interacting with torrent files but not a total nightmare.” ↩
-
It’s possible to just directly edit bencoded objects, but we don’t make a habit of inviting hell into our minds by passing around anonymous dicts. ↩
-
More to come, including embedding a first-party tracker, description metadata in the usual places, and json-ld in unusual places. ↩
-
although while i am writing this i am realizing we need to also display it on sciop, so by the time you read this that will likely already be done. ↩
-
See the docs for more information on the service and the configuration ↩
-
In our experience, it is typically the incoming connections that are blocked, rather than outgoing, and it is possible to download a torrent with a client or a tool like aria2 even when seeding is impossible. ↩
-
S3 is just HTTP!!! All data hosted in buckets is now in play. E.g. if your AWS S3 bucket was
smithsonian-open-access, the HTTP url is justhttps://smithsonian-open-access.s3.amazonaws.com/and all the paths, or prefixes, whatever they call them, are the same. ↩ -
or the fediverse, as is more often the case. ↩
-
e.g. if they are subscribed to the relevant torrent .rss feed ↩
-
Once for the initial hashing, once for initial seeding to the swarm ↩
-
~ user experience ~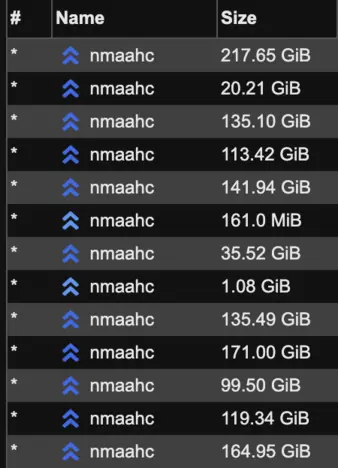 ↩
↩