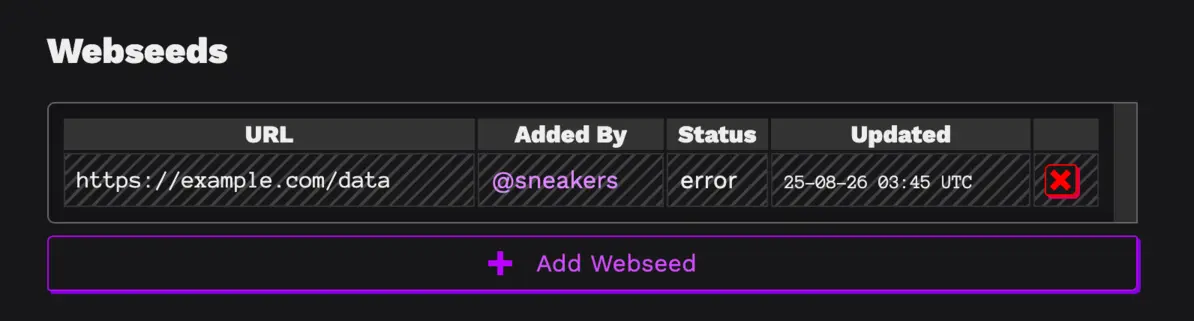
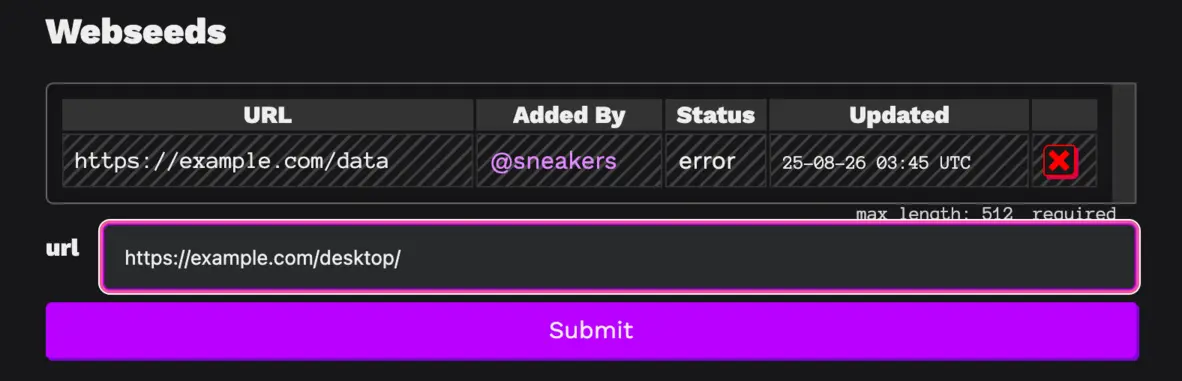
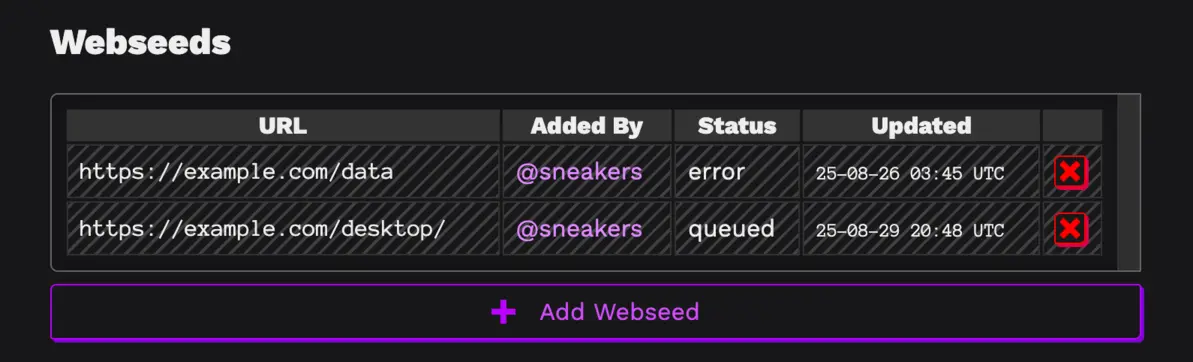
In addition to the sciop blog existing, now it is embedded on the frontpage of sciop dot net, a routine feature for a website that has most of its core components relatively squared away.
The Pull Request, first initiated by transorsmth some 3 months ago: https://codeberg.org/Safeguarding/sciop/pulls/404
As with all new development on sciop, it is intended to be configurable by other instances aside from sciop dot net, when such things exist, and can accept multiple atom feeds for e.g. different topics, covering different projects, with different authors, and so on.
So without further ado, a screenshot of text of the other two posts that are also on this website:
A Hint Of Future Plugins
Since this is a very simple feature, and we don’t have much in the way of developer docs at the moment, it seems a good enough example to show the pattern of how most things are implemented in sciop.
It consists of
- A config model -
UpdateFeedsConfig - Some database models -
models/atom.py - A background service to update feeds -
services/atom.py - A job wrapper that links the config to the scheduler -
update_atom_feeds - An API endpoint to generate an HTML partial -
/partials/whatsnew, and - Some templates -
templates/macros/whats-new.html
Pretty much “website things.”
These components (and maybe a handful more) are destined to become the basic of a plugin system, where most current functionality is moved into plugins, and most new functionality is implemented as plugins. There is still a bit of work do be done to get us there, mostly in refactoring the existing templates to support plugins modifying and adding components to them1, and a bit of metaprogramming to wrap API endpoints and handle model migrations, but we have already been writing sciop in separable services with this in mind, so once that is done then that shall be the pattern going forward. As we become a “fediverse app,” the last thing we want to be is “a monolithic fediverse app,” and want to start with a very pluggable design rather than trying to back flexibility into the system later.
For embedding within institutions with rich histories of work patterns and homemade infrastructure, this kind of flexibility and ease of writing custom behavior is essential, and the same is true for supporting different p2p communities. One of the first plugins that we plan on writing after the plugin system lands is integrating external tracker software, where rather than relying on other public trackers, a sciop instance may want to provide its own, embed the tracker link in uploads, generate custom URLs for private torrents to track upload stats, and do all the other fun things one might want from a tracker. We also want to experiment with all the non- or sparsely-implemented FEPs floating around, and will be writing our federation layer as a generic fastapi2 overlay that can be useful outside sciop.
Example
To configure feeds, stick something like this in your sciop.yaml
services:
update_feeds:
enabled: true
interval: 10
feeds:
- name: sciop
url: https://blog.sciop.net/feed.xml
with a URL pointing to some atom feed. That’s all that someone using the software would need to do!
That corresponds to boilerplate pydantic models:
class UpdateFeed(BaseModel):
"""
A single feed to use for "whats new" updates
"""
url: AnyHttpUrl
"""URL of an Atom feed"""
name: str
"""
Short, taglike name to use when displaying posts from this feed.
"""
class UpdateFeedsConfig(JobConfig):
"""
A set of feeds and service config for updating them
"""
interval: int = 30
"""
Frequency (in minutes) to check feed for updates.
If the feed has not been updated in that time, no changes are made to local objects.
"""
feeds: list[UpdateFeed] | None = None
"""
Potentially multiple feeds to pull updates from.
If `feeds` is not provided, service will be disabled.
"""
max_n_posts: int = 10
"""
Only keep the last n posts from each configured feed.
"""
Internally, that config is used by function wrapper that schedules the service:
@scheduler.interval(
minutes=get_config().services.update_feeds.interval,
enabled=bool(
get_config().services.update_feeds.enabled and
get_config().services.update_feeds.feeds
),
)
async def update_atom_feeds() -> None:
"""
Put documentation in the real thing, but this is merely a simulacrum
"""
await services.update_feeds()
and then the scheduler will launch a task every interval minutes to update the feed.
Simple as pie. the rest are details.
Appendix - Build and Deploy a Static Site with Codeberg/Forgejo using Webhooks
If you are unsure how one might go about making an atom feed -
We write this very blog with jekyll,
generate the feed with jekyll-feed,
and use a webhook to trigger a rebuild on push on one of our machines.
Total time from push to deployment is ~8 seconds or so.
I wasn’t able to find another blogpost describing this exact process, since the forgejo webhook documentation is a little sparse. So if it saves anyone time…
- generate a secret with
openssl rand -hex 32 - configure a webhook like this:
[
{
"id": "build",
"execute-command" : "/path/to/your/build/command.sh",
"command-working-directory": "/wherever/your/blog/repo/is",
"response-message": "Deployed!",
"trigger-rule": {
"and": [
{
"match": {
"type": "payload-hmac-sha256",
"secret": "{YOUR_SECRET}",
"parameter": {
"source": "header",
"name": "X-Forgejo-Signature"
}
}
},
{
"match": {
"type": "value",
"value": "refs/heads/main",
"parameter": {
"source": "payload",
"name": "ref"
}
}
}
]
}
}
]
- for a build script
/path/to/your/build/command.shlike this3:
#!/bin/bash
git pull
/home/webhook/.rbenv/shims/bundle install
/home/webhook/.rbenv/shims/bundle exec jekyll build -d /some/web/directory
- configure nginx to forward the URL to the webhook service4
server {
listen 443 ssl;
server_name your.url.here;
root /some/web/directory;
location / {
try_files $uri $uri/ $uri.html =404;
}
location /hooks/ {
proxy_pass http://localhost:9000/hooks/;
}
# other stuff for ssl and logging and ratelimiting and etc.
}
- Configure a webhook for your repository,
- POSTing JSON
- to your hooks url
- with the secret generated above,
- on push events
- with a branch filter for
main.
and ka blammo. push to deploy the blog, and sciop will catch up when it runs its next update.
Now you’re talking to online from your personal computer.
-
One can already override any template by configuring
paths.template_overridewith a directory of template overrides. E.g. to overridesrc/sciop/templates/pages/datasets.html, one would write their own template and put it in{template_override}/pages/datasets.html. ↩ -
Or, we may jump ship to litestar, since contributing to fastAPI has proven to be infuriating, and the non-bot PR merge rate can attest to that. ↩
-
After installing rbenv and ruby, if you aren’t using jekyll then obviously do whatever your thing is to build it obvi ↩